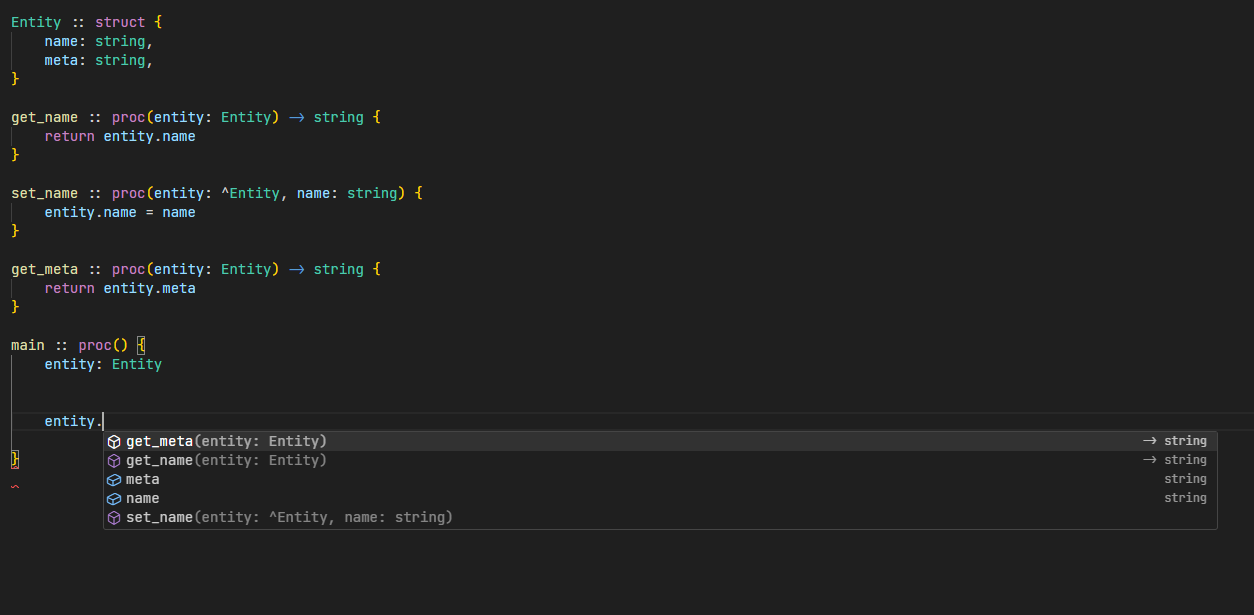
Ols is a language server for Odin, and works on all the popular text editors.
Why would you want to use ols? #
You might be thinking, “Odin is already such a simple language that any tooling is unnecessary”, but the ability to lookup procedures in a package or goto procedure definitions will radically speed up your coding and understanding of a codebase.
Implementation #
I implemented ols on the idea that the most important thing is fast completion and gotos - everything else is just extra goodness. This means all the extra features cannot affect the performance of completion and goto negatively, or if they do affect it, you have the ability to turn of those features, such as semantic tokens, which have to resolve all the symbols of the current document.
ols consists of the indexer part, which goes through all the packages and stores all relevant ast nodes in a standard map. Every package has its own map index. This is one of the beauties of Odin, that the package system is so well defined and well contained. You rarely have to guess which package the struct, enums, and constants come from, since they have to be explicitly specified. The only exception is using in procedures, where I can’t be certain, and I have to go through all the usings and the current package indexes.
When you are looking at the current document, the indexer is not used, but the actual document ast.
The normal use case is you need to resolve some variable symbol in your document. You start looking at the symbol, jump back to where it’s defined, you then look at the type it has, is it defined in the current package or is it from another package? If it’s in another package, you look at the package index and retrieve the ast node of that. If it’s in the current package of the document, you look in the document ast first, and afterwards in the package index. This basically keeps happening until it finds the final concrete type. This means on completion, the only symbols that gets resolved is the ones relevant to the completion.
Communication #
All request between the client and the server is done through stdout and stdin with the JSON-RPC protocol.
Memory handling #
Every opened document has its own allocator with a fixed size, and relies on the heap allocator if the arena gets full. The temporary allocator is used in handling request from the client, and the allocator gets cleared per request. The indexer uses the heap allocator.
There are still things to consider for the future:
- Should all the packages used be kept in memory at all times?
- Should there be different sized arena for the documents?
Features #
Here you can see some of the main features of ols:
Completion #
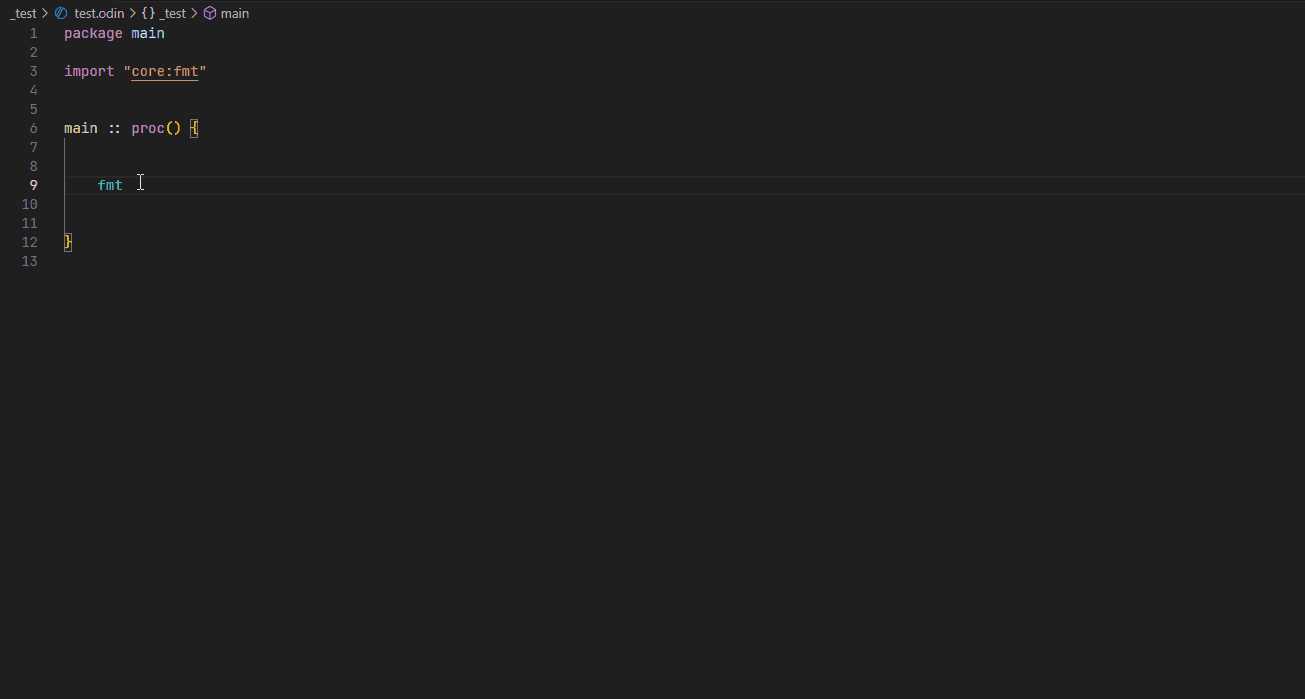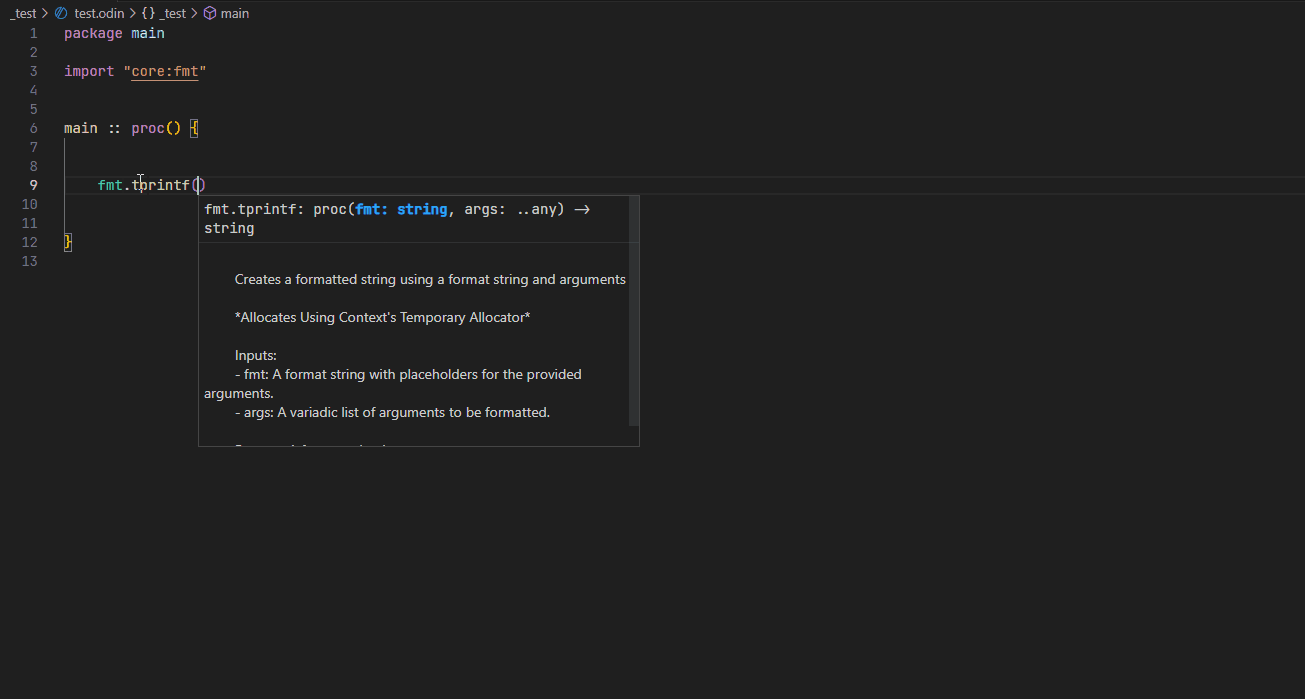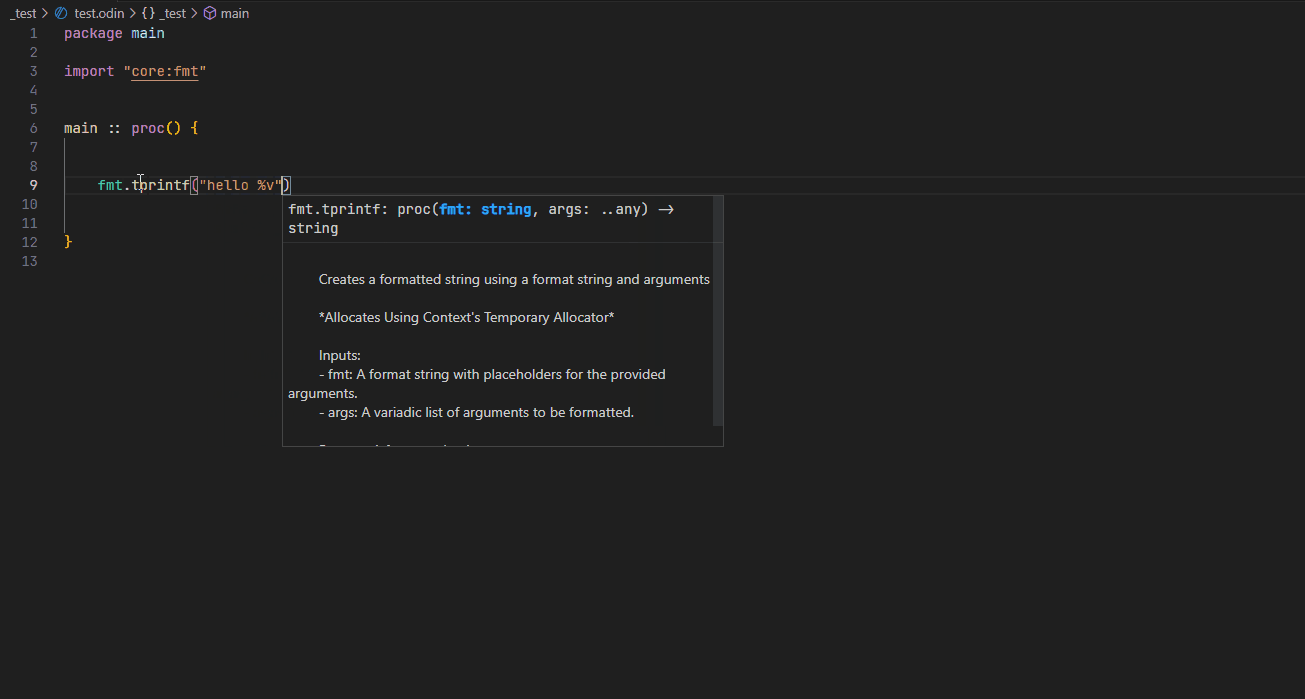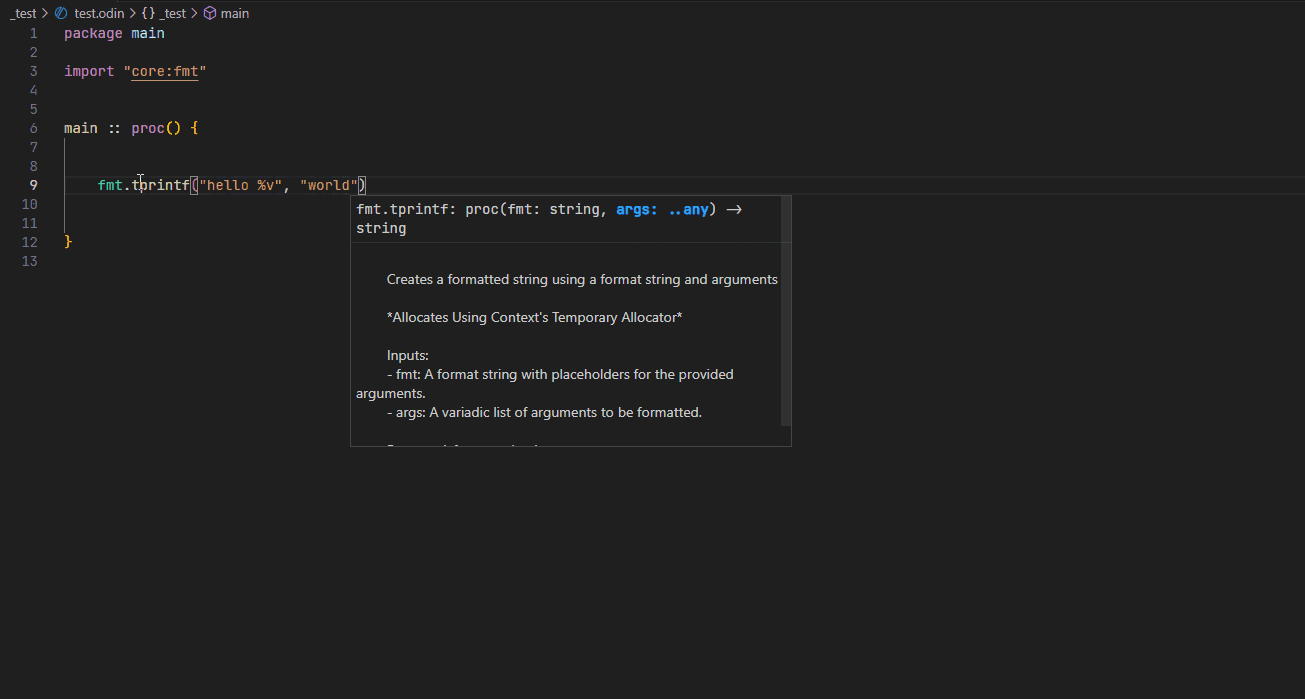
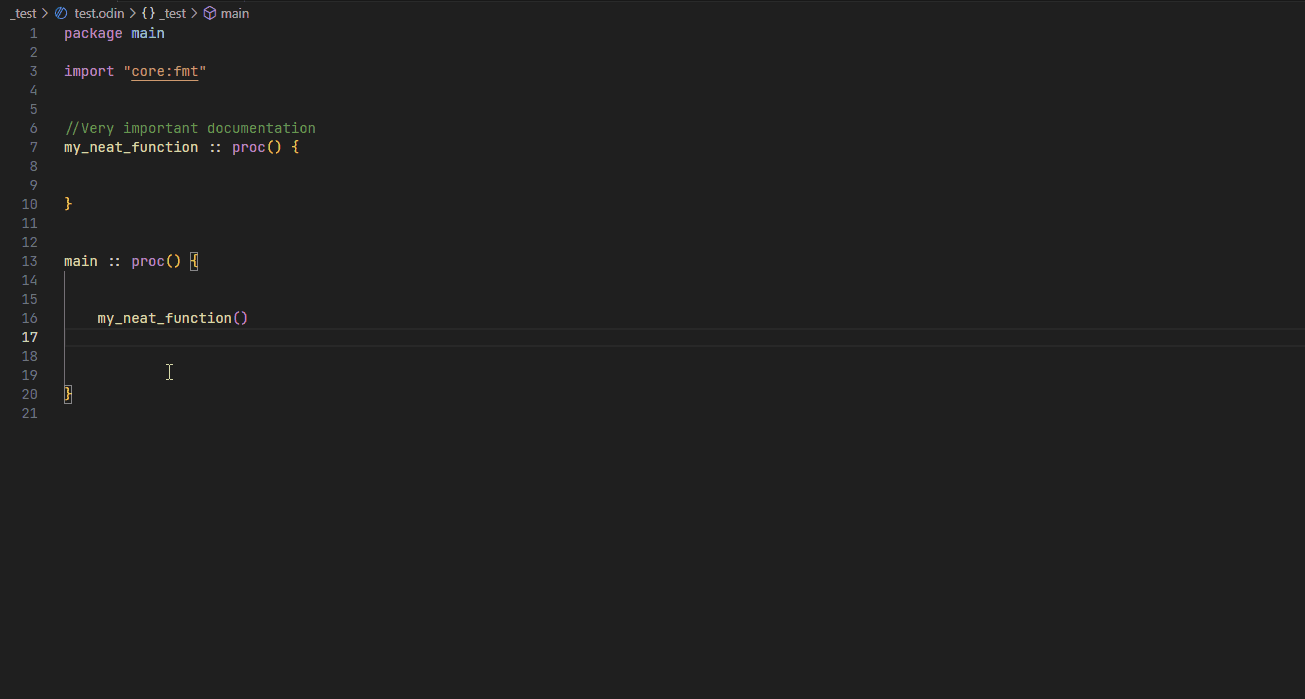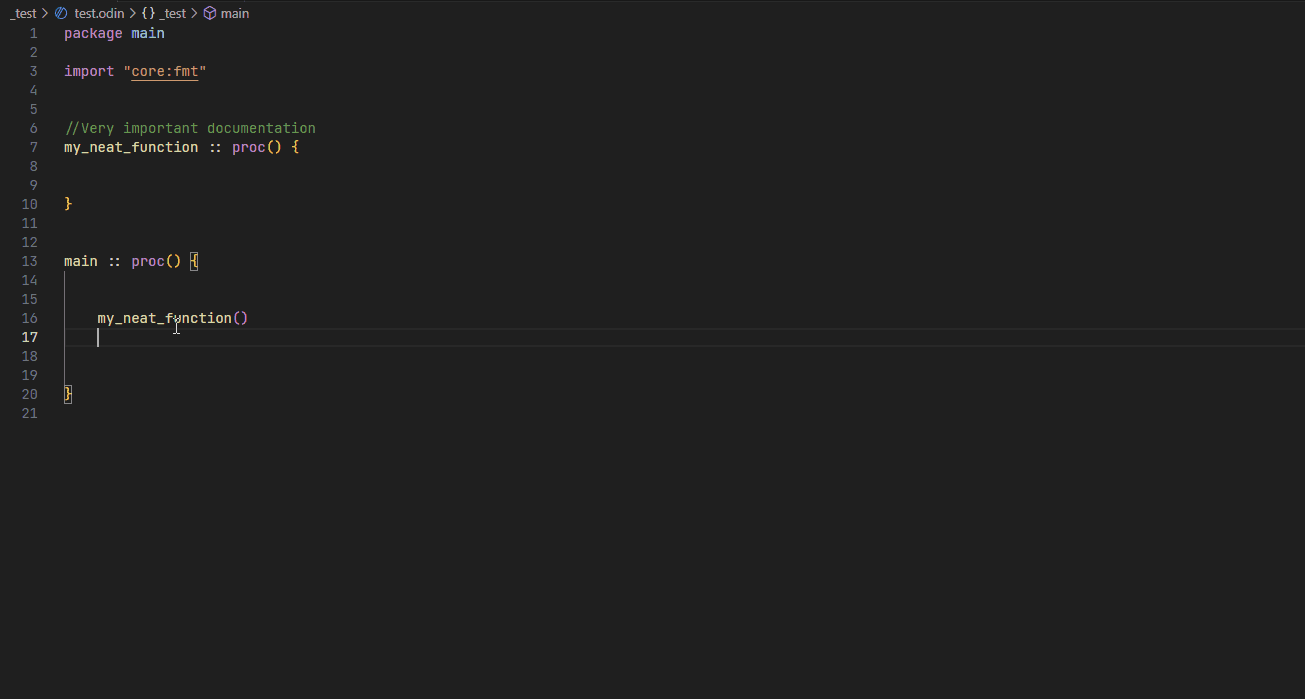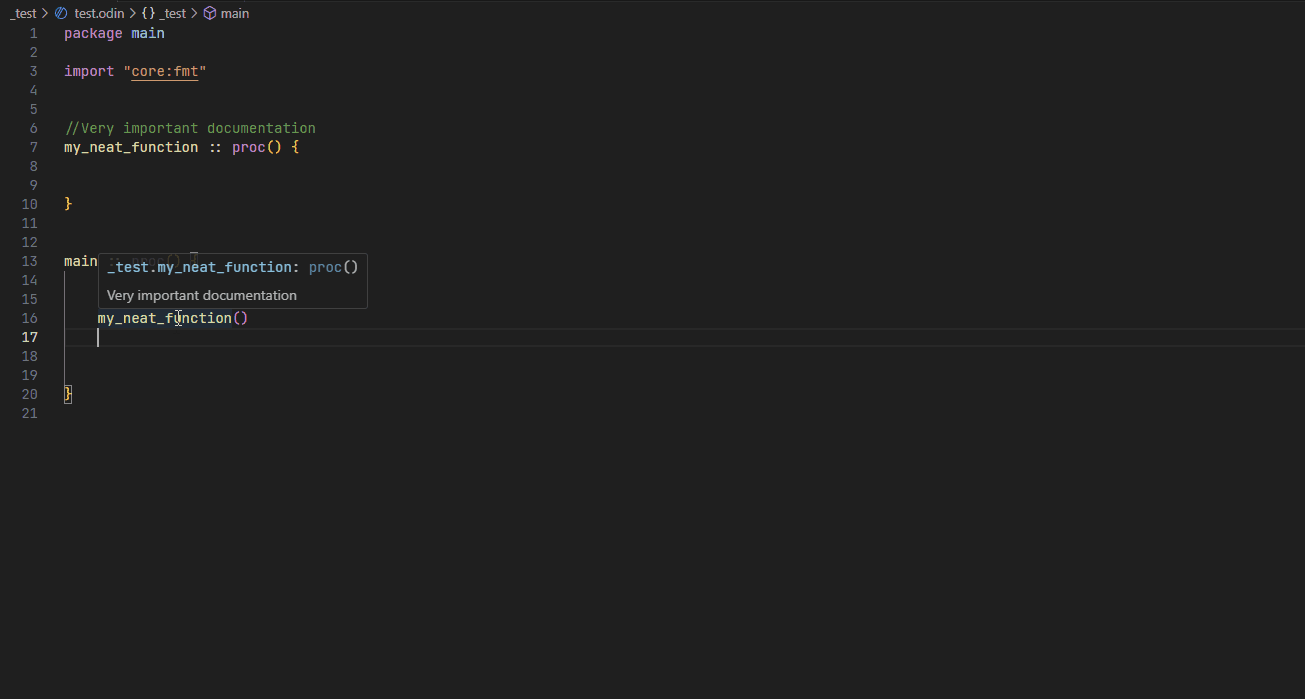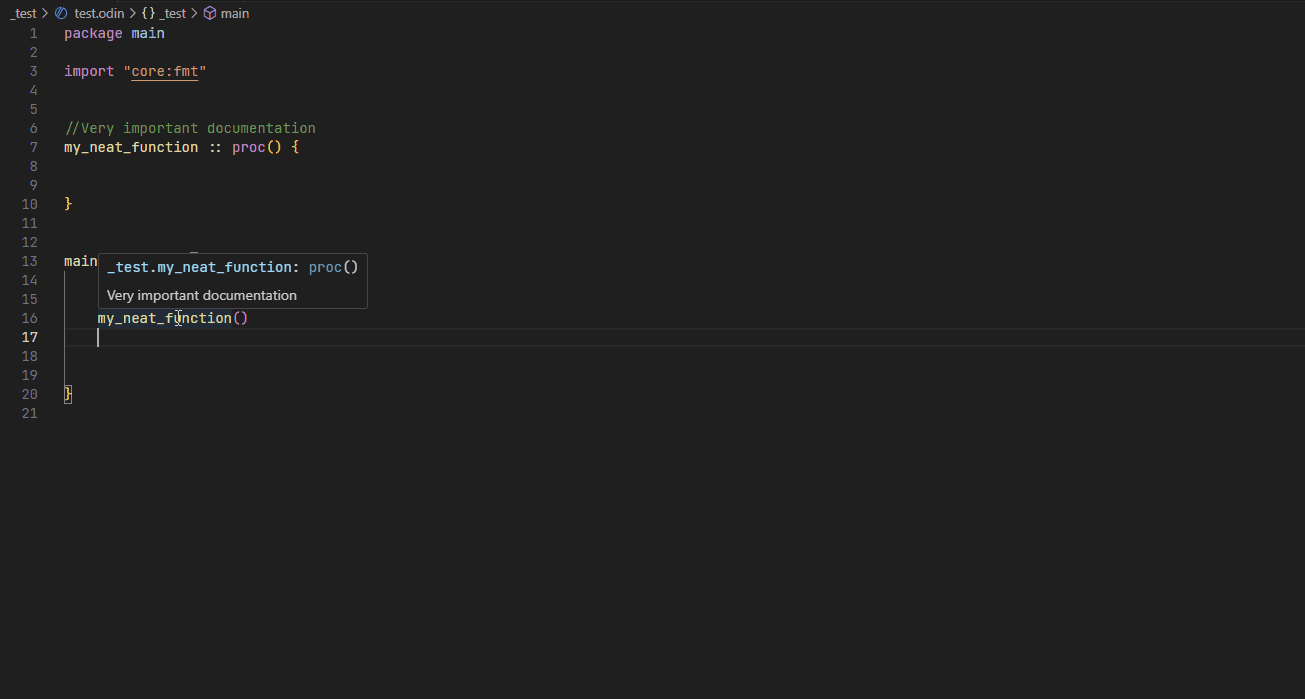
Hover #
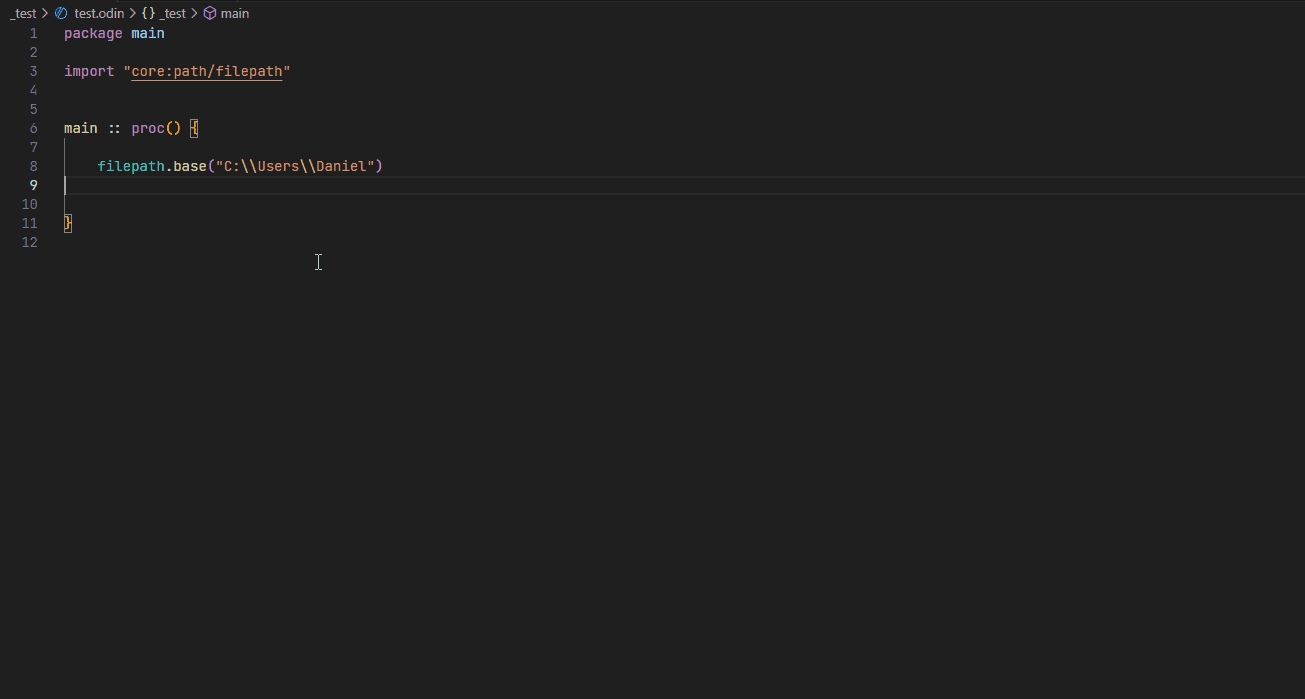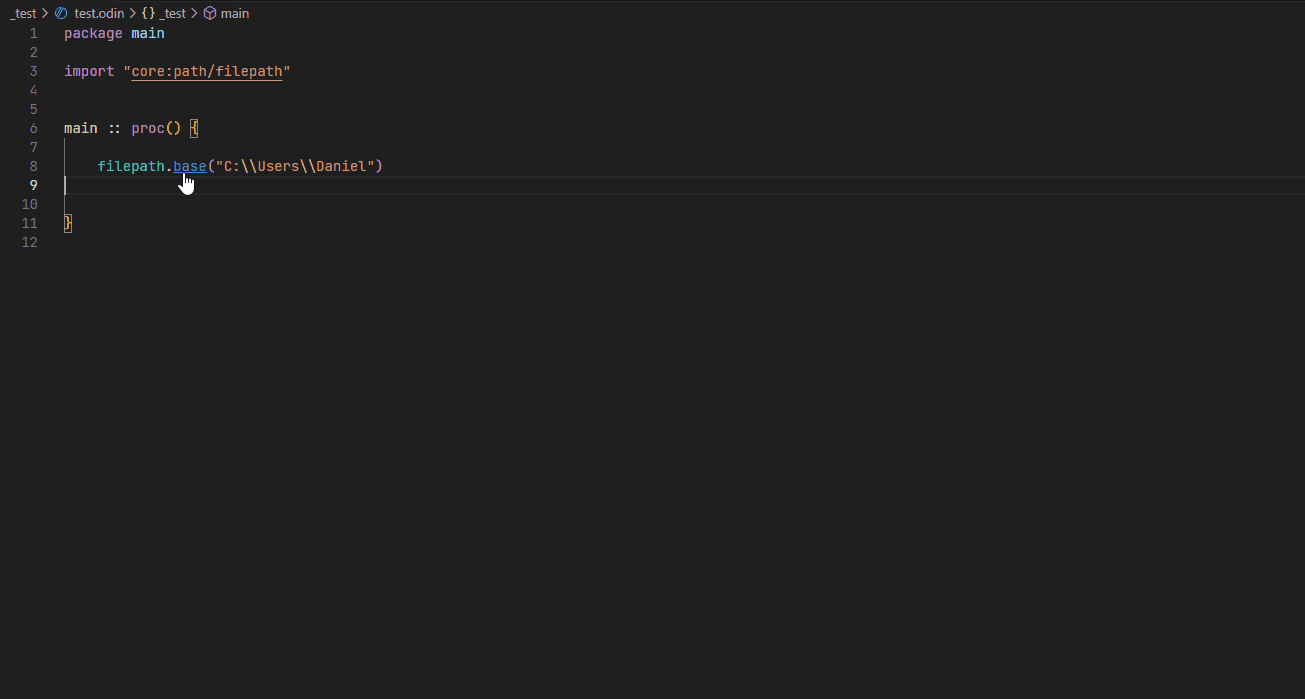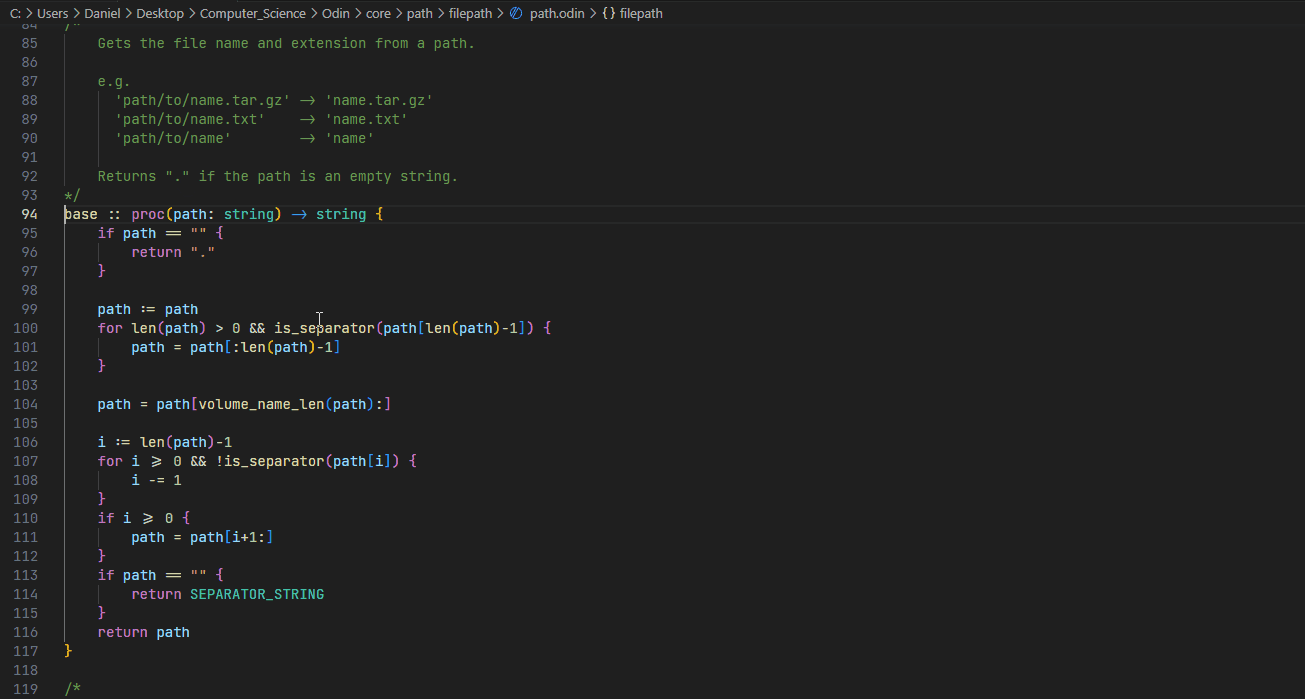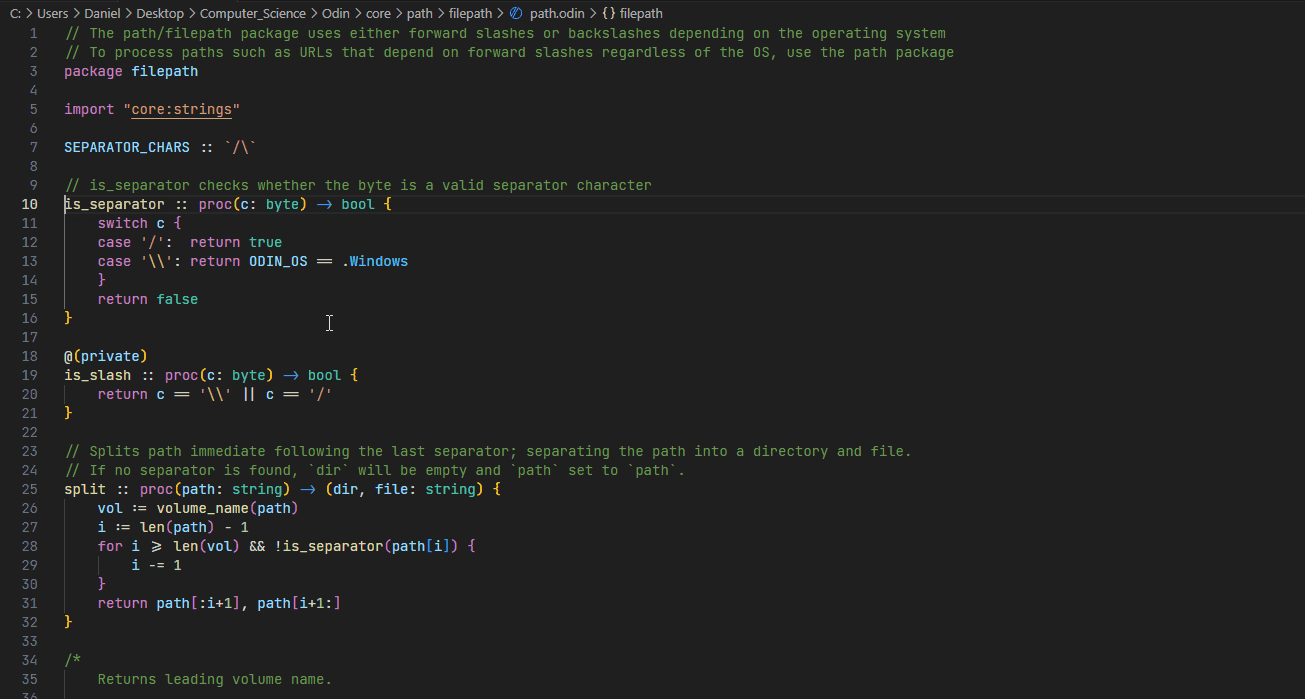
Go to definition #
Fake method completion #